Test-Time Domain Adaptation for Interactive Video Generation

Abstract
Text-conditioned diffusion models have emerged as powerful tools for video synthesis, yet enabling Interactive Video Generation (IVG), where users explicitly control object trajectories, remains challenging. While recent training-free approaches utilize attention masking for guidance, they often trade off perceptual quality for control. In this work, we identify the root causes of this degradation as two distinct domain shifts: (1) internal covariate shift induced by applying masks to pretrained models, and (2) an initialization gap where random noise lacks alignment with trajectory conditions. We propose a test time domain adaptation framework to resolve these shifts. To this end, we first introduce Mask Normalization, a pre-normalization layer that mitigates (1), i.e., covariate shift via feature distribution alignment. Next, a Temporal Intrinsic Prior that enforces spatio-temporal consistency during denoising is introduced to bridge the initialization gap, thus addressing (2). Extensive evaluations on popular dataset demonstrate that our approach outperforms the state-of-the-art IVG methods in both perceptual quality and trajectory adherence.
Project Overview
- Interactive video generation with user guidance
- Domain adaptation for handling appearance and structure variations
- The model generates a video conditioned on user-provided text prompt and bounding-box trajectory
- Text-to-video diffusion models to allow motion trajectory control without requiring any training
- Supports a wide range of object scales and motion paths
- Outperforms SOTA methods on standard benchmarks
Comparison Results
Spider
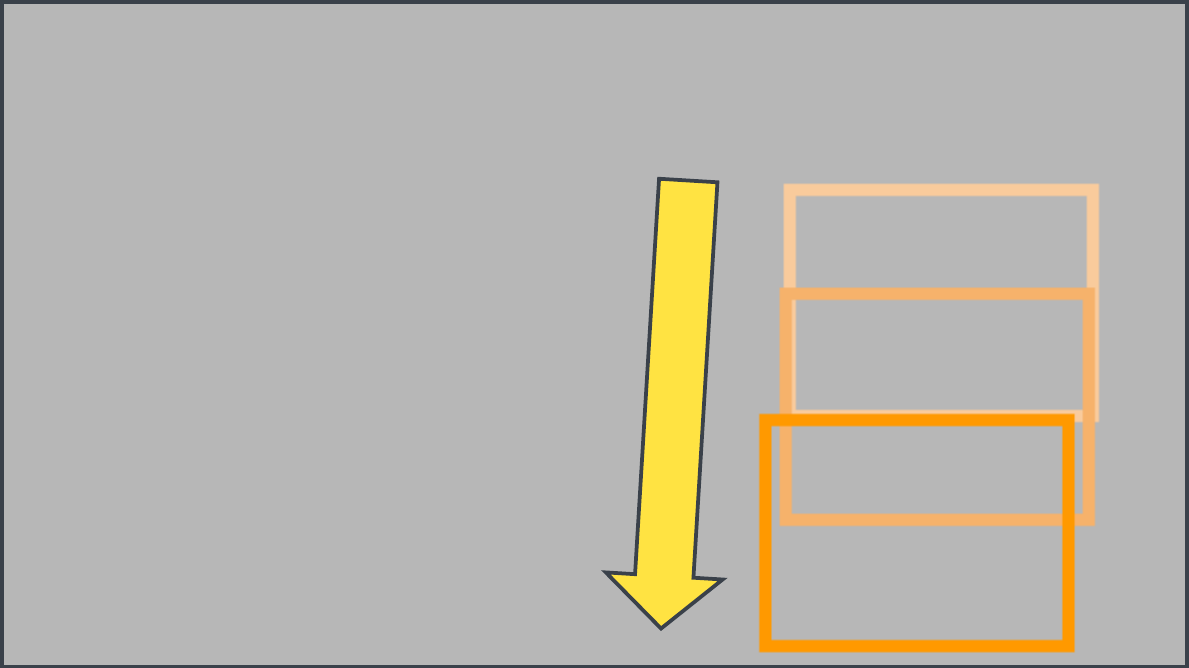
Text Prompt: A spider descending on its web from a branchBounding-box trajectory:
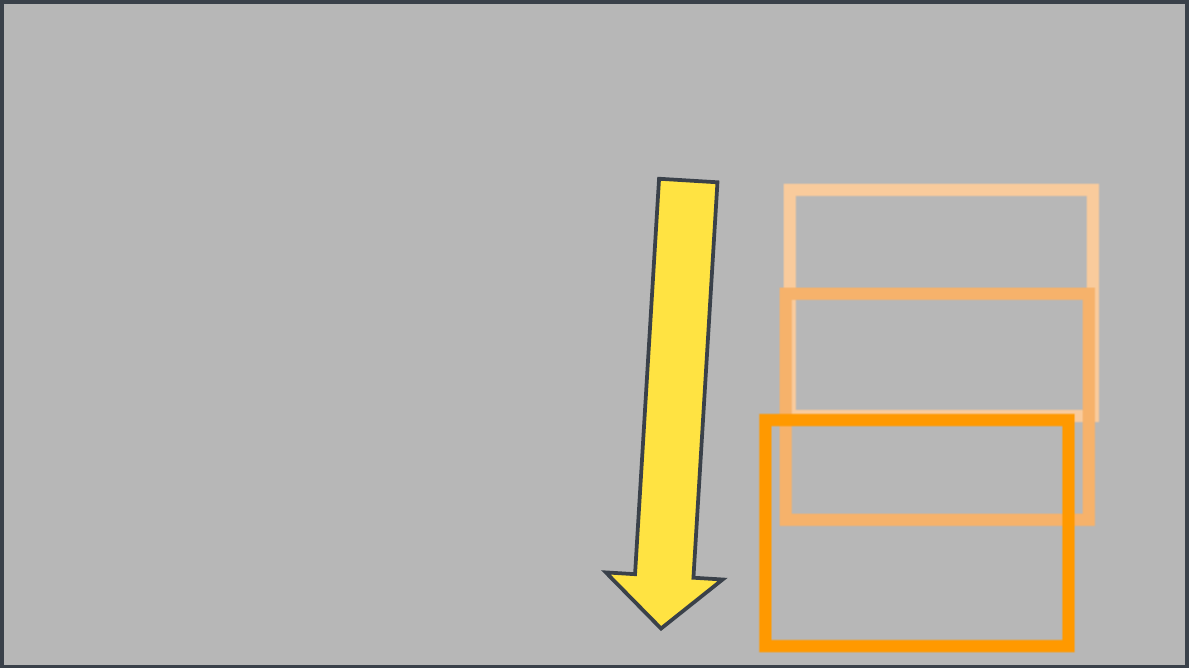
Kangaroo
Text Prompt: A kangaroo hooping down a gentle slopeBounding-box trajectory:
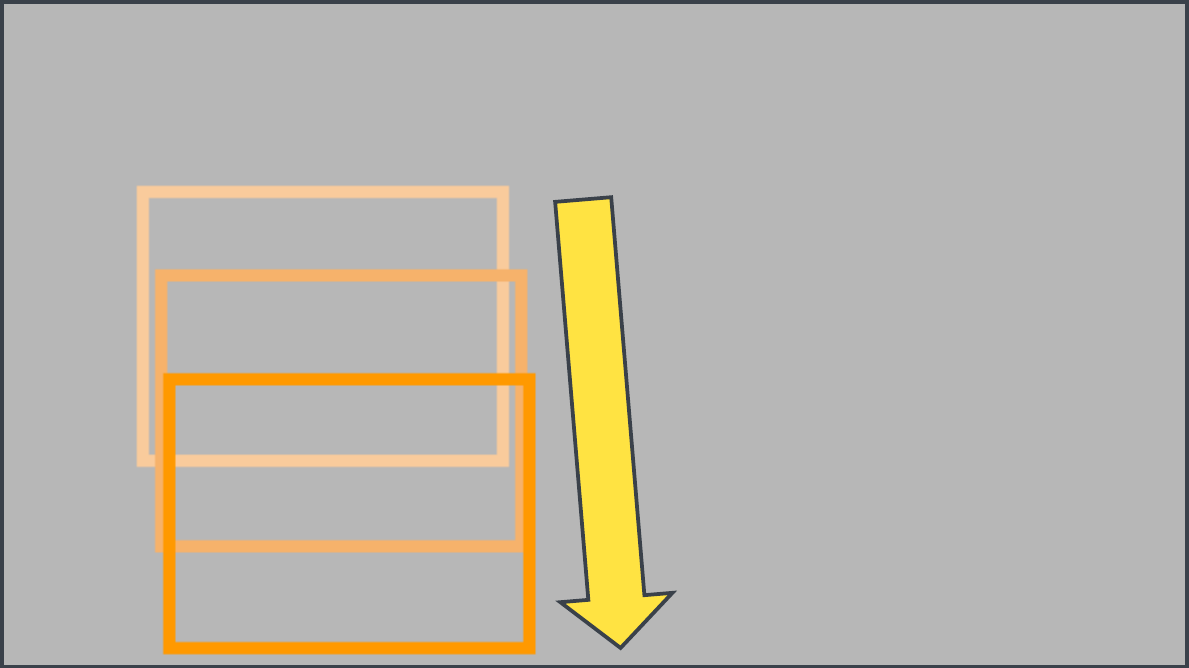
Squirrel
Text Prompt: A squirrel descending a tree after gathering nutsBounding-box trajectory:
Swan
Text Prompt: A Swan floating gracefully on a lakeBounding-box trajectory:

Citation
title={A Dataset and Evaluation for Complex 4D Markerless Human Motion Capture},
author={Rawal, Ishaan Singh and Kumar, Suryansh},
booktitle={Proceedings of the IEEE/CVF CVPR},
year={2026}
}
Contact
For questions or collaborations, please contact Ishaan Singh Rawal or Suryansh Kumar.